海外翻墙免费加速器:[入口]
注意:
1、下面的脚本直接复制无法执行,会有缩进和中英文符号的问题导致脚本无法运行。(可以通过脚本截图进行修改)
2、此脚本主要是用与批量挖掘百度下拉框词的脚本。
如下图:
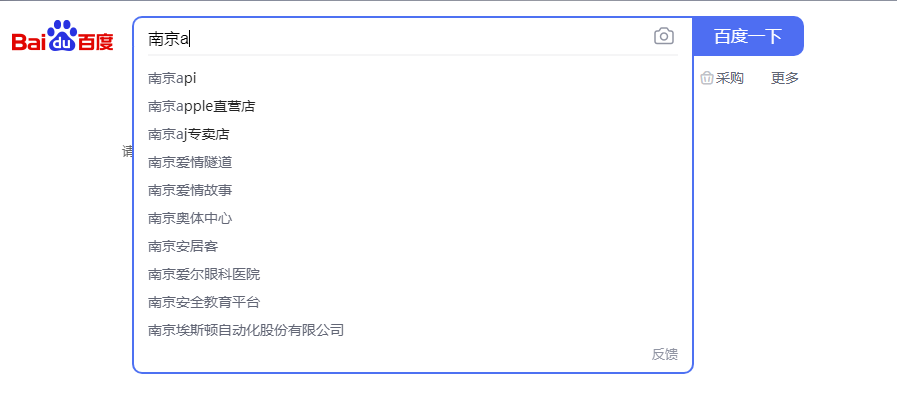
挖掘百度下拉框关键词python脚本
#coding=utf8
import re,requests
import time
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.89 Safari/537.36’,
}
with open (‘word.txt’) as f: #word文件编码必须是utf-8
for i in f:
for q in ‘ abcdefghijklmnopqrstuvwxyz1234567890’: #遍历下拉框
url = ‘https://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=’+i.strip()+q #写入关键词时,百度下拉框响应的接口
print url
html=requests.get(url,headers=headers)
cont = requests.get(url,timeout=120,headers=headers).content
try:
p = re.search( r'{q:\”(.+)”\,p:’, html.content) #通过正则获取
keyword=p.group(1)
q=re.search( r’s:\[(.+)\]}\)’, html.content) #通过正则获取
word=q.group(1).replace(‘”‘,”)
word1=word.split(‘,’)
for p in word1:
txt=open(‘keyword.txt’,’a’)
txt.write(keyword+’:’+p+’\n’)
time.sleep(0.3)
except Exception:
continue
挖掘百度下拉框关键词python脚本截图如下
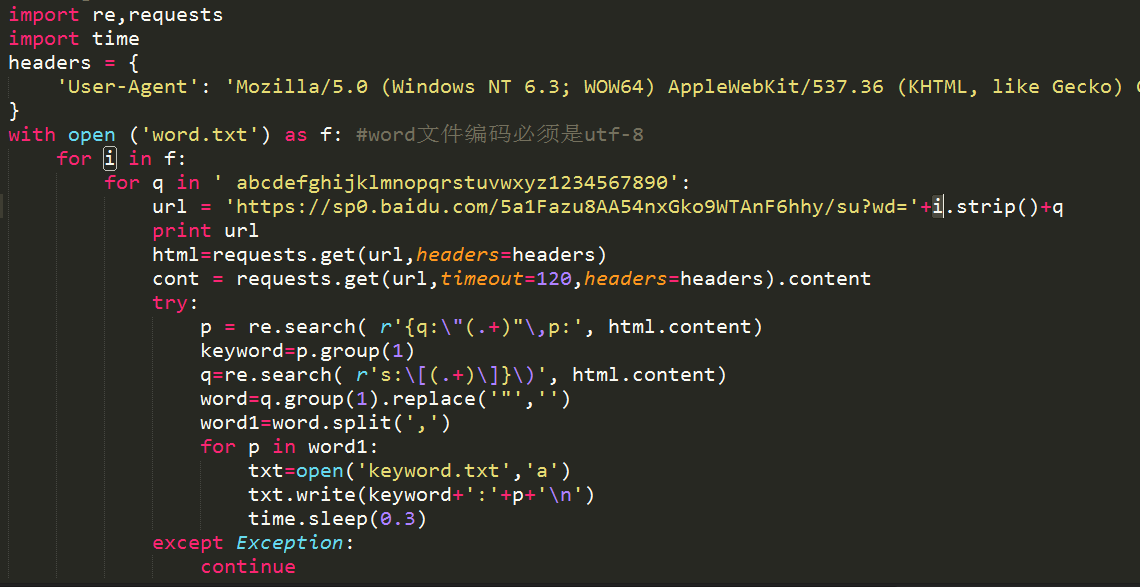
ps:脚本如果直接复制粘贴的话会有语法错误,需要自行修改,由于流量限制不放脚本文件下载,如果有这方面需求的可以联系博主本人(ps:有偿)。
未经允许不得转载:陈海飞博客 » python脚本-挖掘百度下拉框关键词