海外翻墙免费加速器:[入口]
需求:由于最近做了一批百度问答的词,想统计效果,由于数量较多,所以想到了用python抓取实现,以增加工作效率。
通过分析分析发现,浏览量不是静态的,是通过另外一个链接获取的,如下图
链接:https://zhidao.baidu.com/question/751064228438044612.html
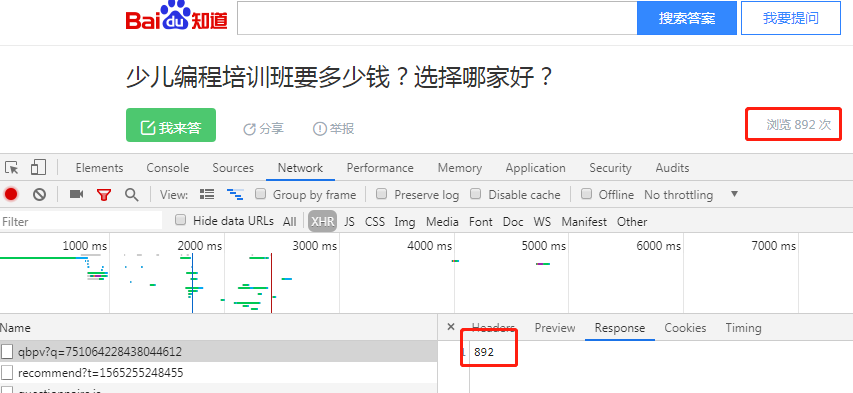
另一个链接主要组成部分是这个页面的id,所以我们只要利用id就可以批量获取页面的浏览量了。
代码如下:
import requests
import time
with open (‘url.txt’) as f:
for i in f:
url = ‘https://zhidao.baidu.com/api/qbpv?q=’+str(i.strip())
url1=’https://zhidao.baidu.com/question/’+str(i.strip())+’.html’
headers = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3’,
‘Accept-Encoding’: ‘gzip, deflate, br’,
‘Accept-Language’: ‘zh-CN,zh;q=0.9,ja;q=0.8’,
‘Cache-Control’: ‘max-age=0’,
‘Connection’: ‘keep-alive’,
‘Cookie’: ‘BAIDUID=A5956C5AF511F049FAC39EF81039120D:FG=1; BIDUPSID=A5956C5AF511F049FAC39EF81039120D; PSTM=1563328175; H_WISE_SIDS=133539_126122_133106_131676_134121_133719_120193_132757_133017_132909_133046_131247_132439_130763_132378_131517_118888_118873_118847_118829_118794_107316_133158_132782_130128_122034_133351_129648_132251_127024_132539_133837_133472_131906_128892_133847_132551_133839_133387_129644_131423_133919_110085_134152_127969_128918_131298_127318_127416_133726_134150_133931; Hm_lvt_4fd9c3ab38c6c37110df1ff930ba679a=1563765503; BDUSS=BlYkcyLUdnMTBZYlBOUmRQajUyZk9LTEp6aFVOOFp6dUtaRTc2SzZJeU1YR3RkSVFBQUFBJCQAAAAAAAAAAAEAAACFJXz0wLbW5r~GvLwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIzPQ12Mz0Nden; IK_FORCE_UHOME=0; ZHIDAO_UHOME_MSGGUID=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; ___wk_scode_token=NZ4OLW9SCElEIw0ykiv5qR3K%2B4RWlXUhx6obejw5ji4%3D; ZD_ENTRY=empty; Hm_lvt_6859ce5aaf00fb00387e6434e4fcc925=1565080978,1565164363,1565168223,1565244568; Hm_lpvt_6859ce5aaf00fb00387e6434e4fcc925=1565244568’,
‘Host’: ‘zhidao.baidu.com’,
‘Referer’:url1,
‘Upgrade-Insecure-Requests’: ‘1’,
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36’
}
print (url)
html=requests.get(url,headers=headers).content
txt=open(‘pv.txt’,’a’)
txt.write(url1+’\t’+str(html)+’\n’)
time.sleep(2)
代码截图如下:
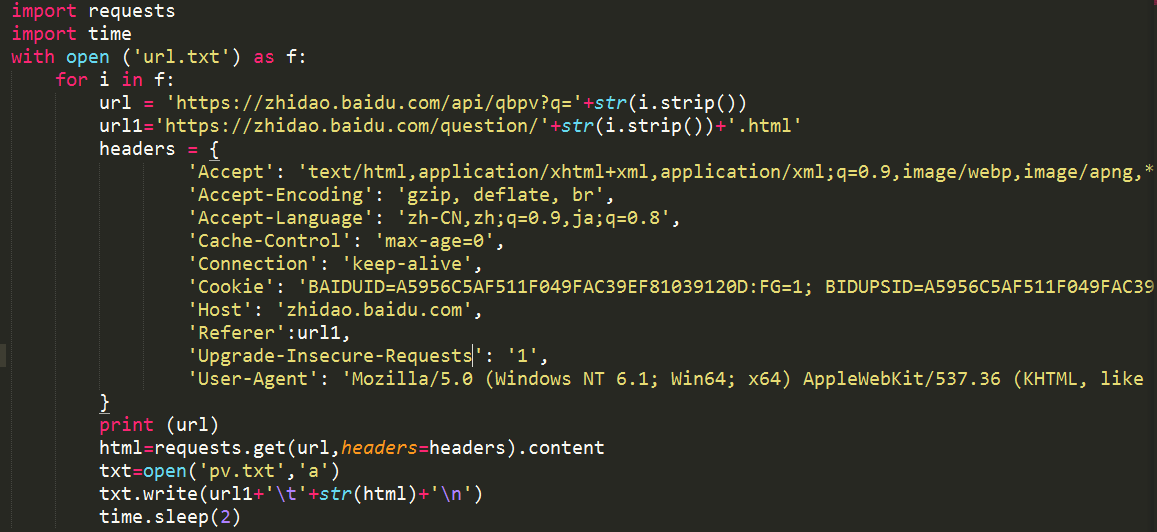
ps:脚本如果直接复制粘贴的话会有语法错误,需要自行修改,由于流量限制不放脚本文件下载,如果有这方面需求的可以联系博主本人(ps:有偿)。
未经允许不得转载:陈海飞博客 » 批量查找百度问答浏览量