海外翻墙免费加速器:[入口]
用robots.txt文件来限制抓取
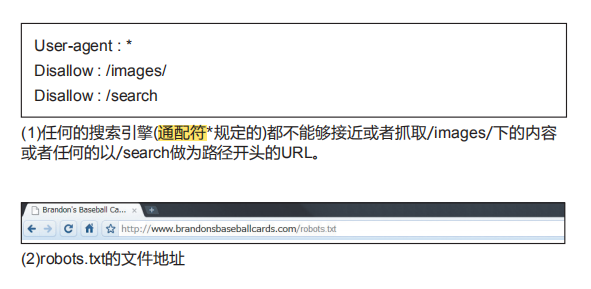
“robots.txt”文件主要用来告知搜索引擎它们是否有权抓取您网站 的特定部分(1)。该文件一定要严格的命名为“robots.txt” , 并被放置在网站的根目录下(2)。
您可能不希望您的网站中的某些页面被抓取 , 也许这些网页在搜索结果中出现对于用户来说并没多大用处。如果您想防止搜索引擎抓取这些页面 , 谷歌网站站长工具中有一个非常好用的robots.txt生成器 , 它可以帮您生成这个文件。需要注意的是 , 如果您的网站使用子域名而您不想被抓取的某些网页恰好在一个特定子域名下 , 您需要为那个子域名创建一个单独的robots.txt文件。如果您想了解更多的关于robots.txt的信息 , 建议您参阅网站管理员帮助中心的关于使用robots.txt文件的指南。
还有很多别的方法可以保证您的网站的某些内容不出现在搜索结果中 , 比如说给您的robots元标签加上“NOINDEX”标识 , 使用.htaccess文件对需要保护的目录加密 , 还可以使用网站站长工具将已经被抓取的网页从搜索结果中移除。Google工程师Matt Cutts在视频中对如何从Google索引中删除内容进行了介绍(英语)。

最佳使用方法
对敏感的内容使用更加安全的方法
您可能不会特别放心仅仅使用robots.txt对敏感的或者保密的内容进行屏蔽。其中一个原因是如果网络上还有一些链接链向这些URL时(比如引用页日志) , 搜索引擎仍然有可能跟踪抓取到您希望屏蔽的URL , 当然 , 它们只会展示您的URL地址信息 , 而不会展示标题或者内容摘要。一些无赖的搜索引擎可能并不会自觉遵守机器人排除标准从而违反您的robots.txt的说明。还有其他原因 , 比如一个好奇的用户可能查看了您robots.txt文件中的目录和子目录 , 并对您不愿对外界展示的内容的URL进行了猜测。使用.htacess文件对内容进行密码保护或者对内容加密是更加安全的措施。
请注意避免 :
1、允许您网站中一些类似搜索结果的页面被抓取到(用户不喜欢刚离开一个搜索结果页面就进入了另一个搜索结果页面 , 这对他们来说没有什么价值)
2、允许大量自动生成的、有相同或极为相似内容的网页被抓取到 , 用户会想 :“难道这100000页近乎相同的网页真的应该在搜索引擎的索引中出现吗?”
3、允许那些因提供代理服务而生成的URL被抓取
未经允许不得转载:陈海飞博客 » 谷歌优化:更加有效地使用robots.txt文件